Deduplicator
The Deduplicator is a tool to remove duplicates from libraries. This tool has two main functions
- To deduplicate a library prior to screening
- To compare two libraries and remove already screened articles
To use this tool, it is important to understand how we define a duplicate. A duplicate is the exact same record that appears twice in your library. A duplicate is not the same article published twice in different journals or a different article with the same name. The function of this tool is to remove duplicate entries of the same record. See this example below - even though the author names are different, these records are otherwise identical, including title, year, journal, volume and page numbers. If you click on the records, you will also see the DOIs are identical. So, even though this record appears slightly differently, it is still a duplicate and has been correctly classified, so no action is needed.
Importing#
- Make an account and log into SRA
http://sr-accelerator.com/ - Export your references from EndNote in XML format
To use the Deduplictor, you will need an exported library of references in XML format. In EndNote, highlight(Ctrl+A)the references you wish you export and click onFile > Export. Under theSave as typedropdown box, selectXML (*.xml). It does not matter which output style you choose. - Upload the file to Deduplicator
In the Deduplicator window, select whether you want to
DeduplicateorRemove Already Screened & Deduplicate. ClickBrowseto select the exported file and press upload, or drag and drop the file. - Name your project (optional)
Name your project by hitting the blue
Editbutton on the top left side of the screen and fill out the name of the project and hit save
Using the Deduplicator#
Deduplicate Function#
We advise using this tool to remove duplicates when conducting a new search across multiple databases for a systematic or other review. The tool will analyse the library you import and sorts records by their likelihood of being a duplicate. This allows for rapid removal of duplicate records.
- Understanding the groups
Once you upload a file, Deduplicator will divide your library into 4 groupsYou will need to work through these groups in varying degrees of detail to finalise removal of duplicates.- Extremely likely duplicates- Highly likely duplicates- Likely duplicates- Non-duplicates - Review Extremely likely duplicates
It is extremely likely that this group will not contain any duplicates. We recommend that you very quickly scan through this group to verify whether there are any incorrectly classified records. - Review Highly likely duplicates
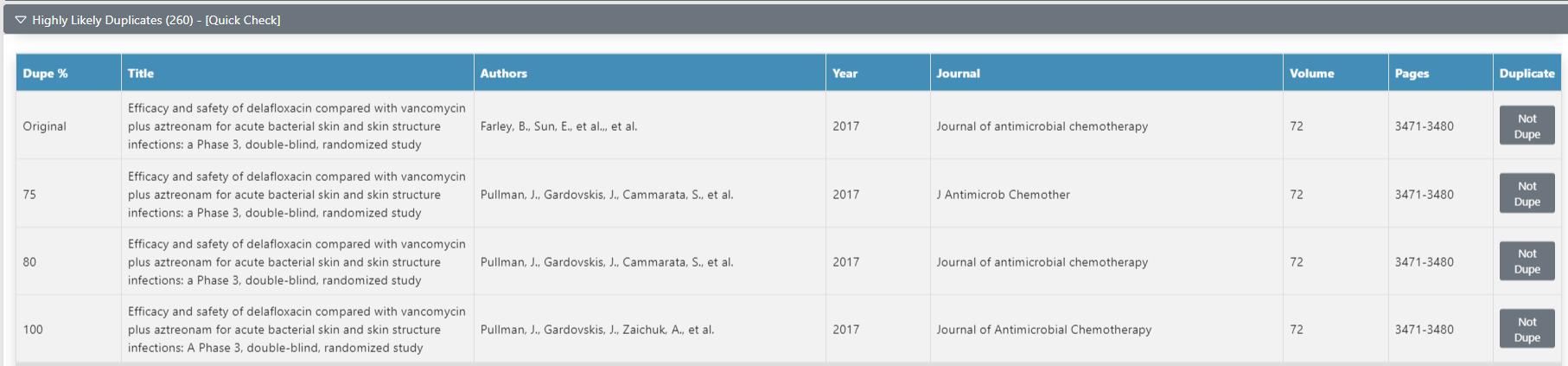
Although unlikely, there may be some incorrectly classified records in this group. We recommend that you do a quick check of these records to identify any false positives. - Review Likely duplicates
This section is likely to contain incorrectly classified duplicates, so we recommend thoroughly checking this section to confirm whether duplicates have been correctly classified. - Overriding the Deduplicator - clicking Not Dupe
Sometimes, Deduplicator will incorrectly classify a record as a duplicate. See the example below - although these articles have identical names, they have different authors, journal, volume and page numbers and are not duplicates. In this example, clickingNot Dupewill send both records to theNon-duplicatessection
- Overriding the Deduplicator - clicking Split group
Sometimes, Deduplicator will incorrectly classify two groups of duplicates as one. See the example below - these 6 articles have identical names, 3 records are by Abrahamian and 3 are by O’Riordan. This group needs to be split -> selectsplit group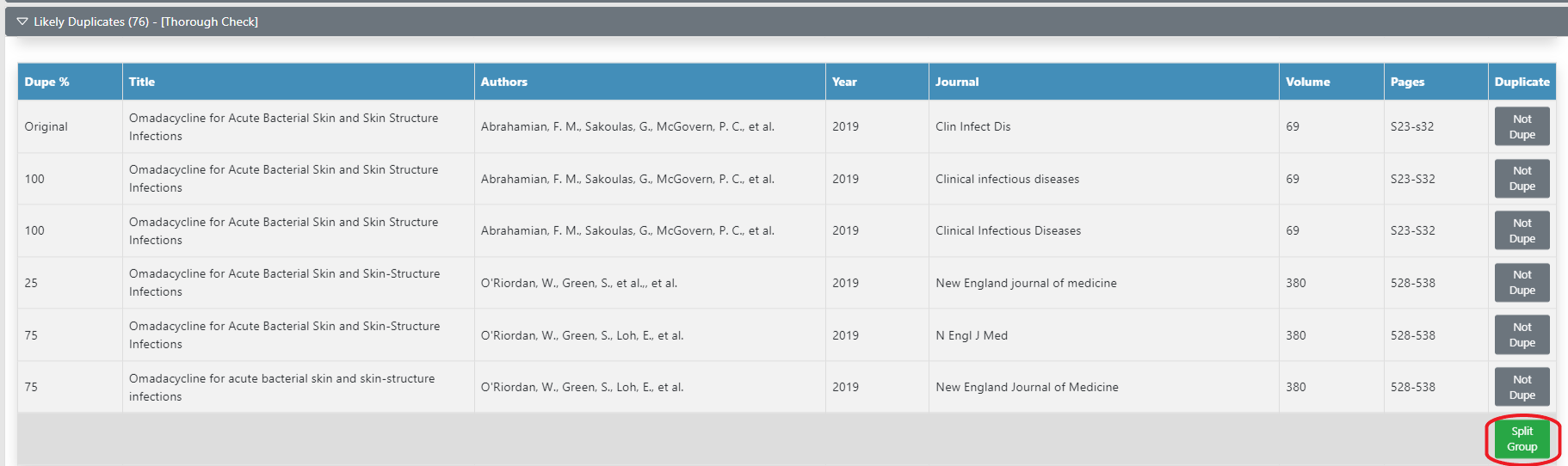 In the pop up, select the references you wish to move to a new group. Click OK.
In the pop up, select the references you wish to move to a new group. Click OK.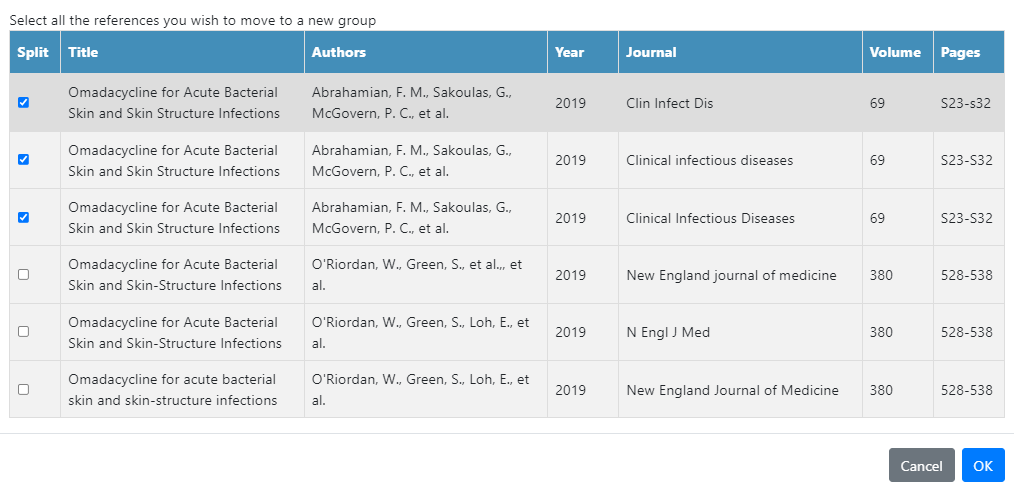 These records will now be in two groups. Deduplicator will automatically retain the first record in the new group, so there is no need to do anything else.
These records will now be in two groups. Deduplicator will automatically retain the first record in the new group, so there is no need to do anything else.
- Deduplication done!
Once you have worked through the first three categories, you have finished deduplicating your library. There is no need to check the Non-duplicates group - we are confident these are all unique records. - Export the library
Once deduplication is complete, clickFile -> exportto select which files to download. You will have options to download all references deduplicated (most relevant for screening), all references, removed duplicate references, and all removed references.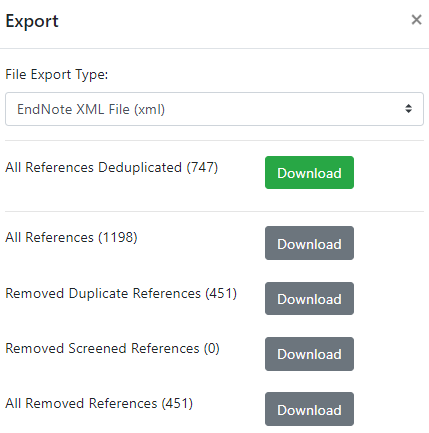
Remove already screened and Deduplicate function#
Two files are uploaded for comparison, and articles appearing in the first library (i.e. those already screened) are removed. At the same time, the tool will analyse the library you import and sorts records by their likelihood of being a duplicate. This tool is most useful when doing citation analysis or updating a systematic review, so you can be sure you aren’t doing the same work twice.
- Upload the files
Follow the same import process as above, but upload two XML files for comparison.
File 1: this is the ‘old library’ perhaps an out of date search or original search file.
File 2: this is the ‘new library’ perhaps an updated search or citation search file. - Deduplicate File 2 - the new library
Go through the deduplication process by following steps 2-5 in the Deduplicate Function section. All functions, such asNot DupeandSplit groupwork the same. File 1 is essentially ignored in this process, you are just looking to identify duplicates within file 2 or the new library - Removing already screened records
You don’t need to do anything special to remove the already screened records. This will automatically happen in the background while you are deduplicating - Export the library
Once deduplication is complete, clickFile -> exportto select which files to download. As with deduplicator, you will have options to download all references deduplicated (most relevant for screening), all references, removed duplicate references, and all removed references. You will also see a 'removed screened references' group - this contains the references you have already screened
Deduplicator FAQs#
Oops! I made a mistake, can I go back?
You’re going through your records and accidentally split a group or select Not Dupe. Don’t worry, you can undo your mistake! Undo or redo by selecting Edit -> Undo or Edit -> Redo. You can also Undo by clicking Ctrl+Z and Redo by clicking Ctrl+Y.
How do I select the article to retain?
Deduplicator will automatically select the first record in the set to keep - there is no need to move the record to the Non-Duplicate group or select Not Dupe.
What do I do if the record is missing information?
Sometimes a record will have incomplete information, for example, missing the journal name or page numbers. When you export, deduplicator pulls information from other duplicate records, so if the journal name is missing from the retained article, this will be collected from another duplicate record for when you re-import to EndNote
Can I see more details about the record?
We have selected the most useful information for identifying a duplicate record, however, if you want to see more information, such as DOI, double click on the record to bring up more information.
I can’t finish this today. Can I save my progress?
Yes! To save, go File -> Save and a .ddpe file will be downloaded. You can then reload this file when you have time to keep deduplicating later by going File -> Load.
Do I need to use both Deduplicate and Removed Already Screened & Deduplicate functions?
No, you can use one or the other. If you want to deduplicate 1 library of screening results, use the Deduplicate function. If you want to deduplicate 1 library and remove results previously screened in another library, use the Remove Already Screened and Deduplicate function.